①直接在主计算芯片下方集成NAND存储单元; ②HBM内存在此架构中仍承担关键角色; ③该方案目前仅停留在专利阶段,CBA堆叠工艺的封装复杂度大幅提升。
《科创板日报》6月22日讯(编辑 宋子乔)近日,闪迪披露的一项专利显示,其正探索一个新的3D堆叠方案,将NAND闪存集成到芯片内部,以缓解当前HBM供应紧张、容量受限及延迟等问题。
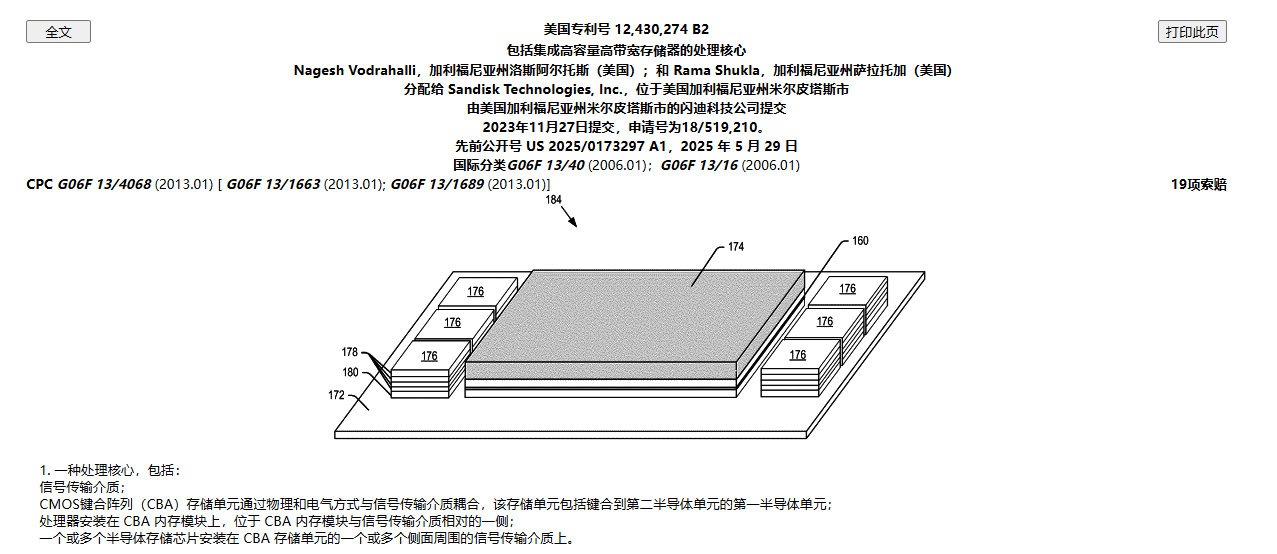
其核心思路是,基于CBA技术,直接在主计算芯片下方集成NAND存储单元,该计算芯片可以是GPU或AI处理器,同时在同一中介层上继续配置HBM堆栈,让HBM与NAND二者分工协作——HBM负责需要即时响应的数据处理,NAND则承担读写操作,以及大模型、海量数据集存储任务。
这种方案试图结合HBM的高带宽与NAND的大容量、低成本优势,并通过近距离宽通道互联,改善数据传输效率,同时降低成本和功耗压力。
闪迪是全球老牌闪存龙头,业务覆盖消费存储卡、企业SSD与AI数据中心存储,长期深耕NAND闪存技术研发。
当前AI训练高度依赖HBM高速内存,但HBM产能紧缺、单价高昂,单堆栈容量仅32-64GB,且只能集成在GPU侧边,数据传输存在延迟。闪迪主营的NAND闪存单位存储成本更低、单盘容量更大,却因距离计算芯片过远,数据传输速度更慢,无法直接承接海量AI数据读写。
为此,闪迪正积极探索新方案,先是推出HBF高带宽闪存方案,模仿HBM垂直堆叠思路,依靠TSV硅通孔多层互联,将多个NAND层垂直堆叠,HBF单堆容量最高可达4TB,明显高于当前HBM水平。
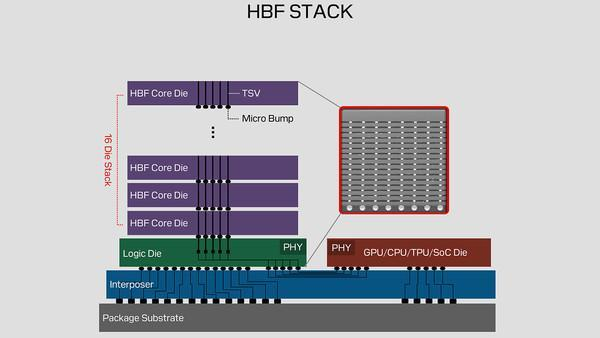
本次新专利更进一步,HBM内存在此架构中仍承担关键角色,但功能定位发生根本性转变。其不再作为主要存储介质,而是专注于处理实时性要求极高的指令缓存与权重参数,HBM的利用率有望进一步提升。
不过,该方案目前仅停留在专利阶段,封装复杂度、散热功耗、量产成本都是待攻克难题,商业化面临多重挑战。
该方案的关键在于CBA堆叠工艺。CBA全称CMOS directly Bonded to Array(控制电路直接键合存储阵列),是闪迪和铠侠联合研发的新一代3D闪存堆叠技术,其优势在于,存储与控制晶圆分开制作,互不干扰,闪存堆叠层数、读写性能大幅提升,但对晶圆纳米级贴合精度要求极高,设备与双片硅片将大幅拉高制造成本,量产良率管控难度大。
另外,成本问题同样严峻,初步估算采用该架构的AI加速器单价将上涨40%,这可能限制其在消费级市场的推广。散热设计也需要重新构建,垂直堆叠结构无疑会增加热点密度。